
Github 참조
onlybooks/pytorch: 파이토치 딥러닝 마스터 (github.com)
GitHub - onlybooks/pytorch: 파이토치 딥러닝 마스터
파이토치 딥러닝 마스터. Contribute to onlybooks/pytorch development by creating an account on GitHub.
github.com
개인 공부 할 때 적은 것으로, 코드 위주로 설명됩니다. (추후 내용 추가 될 수 있음)
4.1 ~ 4.2절까지
1차 수정 완료 (07.25)
4.1 이미지 다루기
4.1.1 컬러 채널 더하기
우리가 접할 수 있는 이미지 포맷을 읽어서 파이토치에서 기대하는 방식에 맞춰 이미지의 다양한 부분을 담은 텐서 표현으로 데이터를 변환해야 한다.
이미지는 픽셀 단위의 높이와 너비를 가지는 표준적인 그리드에 나열된 복수 개의 스칼라 값 모음으로 표현된다.
* 이미지 파일은 위에 올린 Github을 참조해주세요. data -> p1ch4로 들어가면 다운 받을 수 있습니다.
4.1.2 이미지 파일 로딩
import imageio
img_arr = imageio.imread('../data/p1ch4/image-dog/bobby.jpg')
#https://github.com/onlybooks/pytorch/tree/master/data/p1ch4
img_arr.shape
결과
[720, 1280, 3]
코드 설명
코드의 img는 너비와 높이에 해당하는 두 개의 공간 정보와 RGB 채널에 해당하는 세 번째 차원까지 합하면 3차원 배열 같은 넘파이 객체다.
C X H X W (채널, 높이, 너비 순으로 배치)
4.1.3 레이아웃 변경하기
구식의 차원 레이아웃에서 적절한 레이아웃을 얻기 위해 새로운 차원으로 변경하려면 텐서의 permute메소드를 사용한다.
앞에서 얻은 H X W X C 입력 텐서에 대해 채널2와 채널0 그리고 채널 1 순으로 나열되도록 변경하면 적절한 레이아웃이 된다.
하나의 이미지
img = torch.from_numpy(img_arr)
out = img.permute(2, 0, 1)
코드 설명
(720, 1280, 3) -> (3, 720, 1280)이 된다.
* 딥러닝 프레임워크마다 레이아웃이 다르다는 것을 명심해둡시다.
여러 장의 이미지
첫번째 차원에 여러 이미지를 배치(batch)로 넣어 N X C X H X W 텐서로 저장하자.
batch_size = 3
batch = torch.zeros(batch_size, 3, 256, 256, dtype=torch.uint8)import os
data_dir = '../data/p1ch4/image-cats/' # https://github.com/onlybooks/pytorch/tree/master/data/p1ch4
filenames = [name for name in os.listdir(data_dir)
if os.path.splitext(name)[-1] == '.png']
for i, filename in enumerate(filenames):
img_arr = imageio.imread(os.path.join(data_dir, filename))
img_t = torch.from_numpy(img_arr)
img_t = img_t.permute(2, 0, 1)
img_t = img_t[:3] # <1>
batch[i] = img_t
코드 설명
우리가 만들 배치의 높이는 256, 픽셀 너비는 256 픽셀이며, 이는 RGB 이미지 세 개로 이뤄진 배치임을 의미한다.
4.1.4 데이터 정규화
신경망은 일반적으로 부동소수점 텐서를 입력으로 사용한다.
신경망은 입력값이 대략 0에서 1사이거나 -1에서 1사이일 때 훈련 성능이 가장 좋은 특징을 띈다.
-> 텐서를 부동소수점으로 캐스팅하고 픽셀 값을 정규화한다 !
(부동소수점 캐스팅은 쉽지만 정규화는 복잡하다 . . .)
1. 가장 쉬운 방법
batch = batch.float()
batch /= 255.0
코드 설명
픽셀 값을 부호 없는 8비트 정수의 최댓값이 255로 나눈다.
2. 또 다른 방법
n_channels = batch.shape[1]
for c in range(n_channels):
mean = torch.mean(batch[:, c])
std = torch.std(batch[:, c])
batch[:, c] = (batch[:, c] - mean) / std
코드 설명
입력 데이터의 평균과 표준 편차를 구해서 평균이 0이고 각 채널값이 표준 편차를 넘지 않게 만든다.
+) min-max 정규화를 많이 사용하는 것 같다.
데이터의 최소값을 0, 최대값을 1로 변환하며, 중간 값들은 선형적으로 스케일링
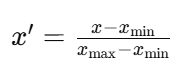
4.2 3차원 이미지: 용적 데이터
4.2.1 특수 포맷 로딩
import imageio
dir_path = "../data/p1ch4/volumetric-dicom/2-LUNG 3.0 B70f-04083"
vol_arr = imageio.volread(dir_path, 'DICOM')
vol_arr.shape
결과
Reading DICOM (examining files): 1/99 files (1.0%99/99 files (100.0%)
Found 1 correct series.
Reading DICOM (loading data): 31/99 (31.392/99 (92.999/99 (100.0%)
(99, 512, 512)
코드 설명
전과는 다르게 채널 정보가 사라져서 파이토치에서 예상하는 레이아웃과 달라졌다.
-> unsqueeze를 사용해서 channel 차원을 위한 공간을 만들어보자.
채널 차원 공간 만들기
vol = torch.from_numpy(vol_arr).float()
vol = torch.unsqueeze(vol, 0)
vol.shape
결과
'파이토치 딥러닝 마스터' 카테고리의 다른 글
| [파이토치 딥러닝 마스터] 4장 (4) (0) | 2024.07.12 |
|---|---|
| [파이토치 딥러닝 마스터] 4장 (3) (0) | 2024.07.11 |
| [파이토치 딥러닝 마스터] 4장 (2) (0) | 2024.07.10 |
| [파이토치 딥러닝 마스터] 3.8 텐서 메타데이터: 사이즈, 오프셋, 스트라이드 (2) | 2024.07.08 |
| [파이토치 딥러닝 마스터] 3.4 이름이 있는 텐서 (2) | 2024.07.05 |